

기초부터 다지는 ElasticSearch 운영 노하우 1-2장을 읽고 요약하였습니다.
1. Elasticsearch 소개 및 특징
Elasticsearch란
Elasticsearch 는 루씬 기반의 오픈소스 검색엔진이다. JSON 기반의 문서를 저장하고 검색할 수 있으며 문서들의 데이터를 기반으로 분석 작업이 가능하다.
특징
특징 | 설명 |
준실시간성 | 실시간이라고 생각할 만큼 색인된 데이터가 매우 빠르게 검색됨 (실시간은 아님) |
클러스터 구성 | 한 대 이상의 노드를 클러스터로 구성하여 안정성을 보장하고 부하 분산이 가능 |
스키마리스(schemaless) | 입력된 데이터에 대해 미리 정의하지 않아도 동적으로 스키마 생성 가능 |
Rest API | SQL이 아닌 Rest API 기반의 쉬운 인터페이스를 제공하여 비교적 진입장벽이 낮음 |
2. Elasticsearch의 기본동작
실행하기
# docker를 활용하여 실행
> docker run -p 9200:9200 -p 9300:9300 -d --name elasticsearch -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.13.3
# Hello, Elasticsearch
> curl localhost:9200
{
"name" : "f244322eb8b9", # 노드 이름
"cluster_name" : "docker-cluster", # 클러스터 이름
"cluster_uuid" : "yVpdbMETSI29DOBWO6im0w", # 클러스터 uuid
"version" : {
"number" : "7.13.3", # 노드의 Elasticsearch 버전
"build_flavor" : "default",
"build_type" : "docker", # 설치 형태
"build_hash" : "5d21bea28db1e89ecc1f66311ebdec9dc3aa7d64",
"build_date" : "2021-07-02T12:06:10.804015202Z",
"build_snapshot" : false,
"lucene_version" : "8.8.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Bash
복사
문서 색인/조회/삭제/수정
•
검색엔진에서 색인이란 검색을 빠르게 하기 위해 데이터를 저장하는 행위를 말한다.
•
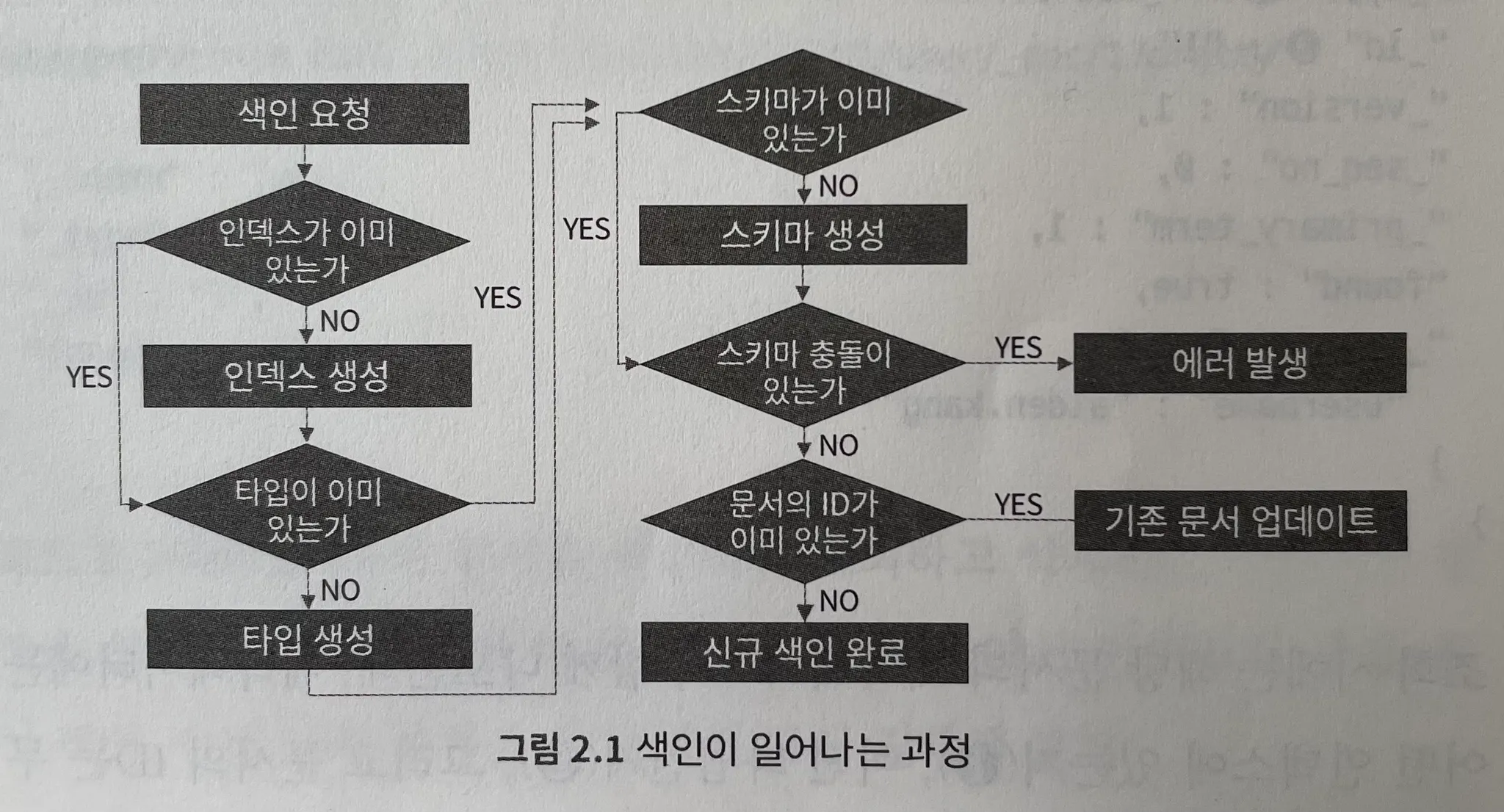
Elasticsearch의 색인 과정
◦
Elasticsearch에서의 색인은 인덱스 생성, 타입 생성, 스키마 생성을 동반한다.
•
문서의 색인과 조회 (id 지정시)
# id=1로 지정하여 색인(PUT)
> curl -XPUT "http://localhost:9200/books/_doc/1" -H 'Content-Type: application/json' -d '{
"title" : "Elasticsearch Guide",
"author" : "Kim",
"date" : "2014-05-01",
"pages" : 250
}'# id=1로 색인된 문서가 결과로 출력
# 조회
> curl -XGET http://localhost:9200/books/_doc/1
Bash
복사
•
문서의 색인과 조회 (id 미지정시)
# id 지정없이 색인(POST)
> curl -XPOST "http://localhost:9200/books/_doc" -H 'Content-Type: application/json' -d '{
"title" : "Elasticsearch Guide ",
"author" : "Kim",
"date" : "2014-05-01",
"pages" : 250
}'# ${생성된ID}와 함께 색인된 문서가 결과로 출력
# 조회
> curl -XGET http://localhost:9200/books/_doc/${생성된ID}
Bash
복사
•
문서 삭제
> curl -XDELETE "http://localhost:9200/books/_doc/1
# 삭제 결과 출력
# 삭제된 문서를 조회할 경우 found=false 결과가 나옴
Bash
복사
•
인덱스 생성 및 조회
# contents 인덱스 생성
> curl -XPUT "http://localhost:9200/contents"# 모든 인덱스 목록 및 확인
> curl -XGET "http://localhost:9200/_cat/indices/contents"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open books fUYfNR_TSiaTF7uvntj7lw 1 1 1 10 12.4kb 12.4kb
yellow open contents YuRJSf7qRAee9o1hYdgtoA 1 1 0 0 208b 208b
Bash
복사
•
스키마 확인 (인덱스의 필드와 타입 확인)
# books 인덱스의 스키마 확인
> curl -XGET "http://localhost:9200/books/_mappings?pretty"
{
"books" : {
"mappings" : {
"properties" : {
"author" : { # author 필드
"type" : "text", # 타입: 문자열
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"date" : { # date 필드
"type" : "date" # 타입: 날짜
},
"pages" : { # pages 필드
"type" : "long" # 타입: long
},
"title" : { # title 필드
"type" : "text", # 타입: 문자열
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
Bash
복사
•
문서 수정
◦
색인 후에 동일한 id로 다시 색인할 경우 문서내용의 변경과 함께 _version은 증가하고 result는 updated로 변경됨
◦
스키마가 정의되어 있다하더라도 새로운 필드가 추가되면 해당 필드가 색인되고 스키마도 추가로 정의된다.
◦
기존의 필드와 충돌하는 타입으로 새로운 문서가 인입될 경우 스키마 충돌 에러가 발생하고 색인이 실패한다.
문서 검색하기
•
색인한 문서는 다음과 같이 검색이 가능하다.
•
curl -XPOST localhost:9200/_bulk -H 'Content-Type: application/json' -d '{ "index" : { "_index" : "books", "_type" : "_doc", "_id" : "1" } }
{ "title" : "Elasticsearch Guide", "author" : "Kim", "pages" : 250 }
{ "index" : { "_index" : "books", "_type" : "_doc", "_id" : "2" } }
{ "title" : "Elasticsearch Easy Guide", "author" : "Lee", "pages" : 300 }
{ "index" : { "_index" : "books", "_type" : "_doc", "_id" : "3" } }
{ "title" : "Elasticsearch Advanced Guide", "author" : "Park", "pages" : 400 }
'
Bash
복사
•
풀스캔 검색: 모든 데이터를 검색
> curl -XGET "http://localhost:9200/books/_search?q=*"# 모든 문서 출력
{"took":43,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":3,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"books","_type":"_doc","_id":"1","_score":1.0,"_source":{ "title" : "Elasticsearch Guide", "author" : "Kim", "pages" : 250 }},{"_index":"books","_type":"_doc","_id":"2","_score":1.0,"_source":{ "title" : "Elasticsearch Easy Guide", "author" : "Lee", "pages" : 300 }},{"_index":"books","_type":"_doc","_id":"3","_score":1.0,"_source":{ "title" : "Elasticsearch Advanced Guide", "author" : "Park", "pages" : 400 }}]}}
Bash
복사
•
문자열 검색: 특정 문자열이 포함된 문서 찾기
> curl -XGET "http://localhost:9200/books/_search?q=Lee"# Lee 문자열이 포함된 문서 출력
{"took":6,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":0.9808291,"hits":[{"_index":"books","_type":"_doc","_id":"2","_score":0.9808291,"_source":{ "title" : "Elasticsearch Easy Guide", "author" : "Lee", "pages" : 300 }}]}}
Bash
복사
•
match 검색: 특정 필드의 값이 조건과 일치하는 문서 찾기
> curl -XGET "http://localhost:9200/books/_search?" -H 'Content-Type: application/json' -d '{
"query": {
"match": {
"pages": 250
}
}
}
'
# pages=250인 문서만 출력
{"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"books","_type":"_doc","_id":"1","_score":1.0,"_source":{ "title" : "Elasticsearch Guide", "author" : "Kim", "pages" : 250 }}]}}
Bash
복사
•
범위 검색: 특정 필드 값의 범위를 지정하여 문서 검색
> curl -XGET "http://localhost:9200/books/_search?" -H 'Content-Type: application/json' -d '{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"pages": {
"gt": 250
}
}
}
}
}
}
'
# pages>250인 문서만 출력
{"took":79,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":2,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"books","_type":"_doc","_id":"2","_score":1.0,"_source":{ "title" : "Elasticsearch Easy Guide", "author" : "Lee", "pages" : 300 }},{"_index":"books","_type":"_doc","_id":"3","_score":1.0,"_source":{ "title" : "Elasticsearch Advanced Guide", "author" : "Park", "pages" : 400 }}]}}
Bash
복사
•
구체적인 검색조건의 차이는 다른 글에서 다룰 예정이다.
문서 분석하기
•
Elasticsearch에서는 색인된 문서를 바탕으로 분석(aggregation)이 가능하다.
•
위의 books 데이터를 활용한다.
•
빈도 세기
# size=0을 조건으로 넣어서 분석결과만 출력하고 검색결과는 생략한다.
> curl -XGET "http://localhost:9200/books/_search?pretty" -H 'Content-Type: application/json' -d '{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "author.keyword"
}
}
}
}
'
# author(저자) 필드를 기반으로 빈도 출력
{
# ...
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Elasticsearch Advanced Guide",
"doc_count" : 1
},
{
"key" : "Elasticsearch Easy Guide",
"doc_count" : 1
},
{
"key" : "Elasticsearch Guide",
"doc_count" : 1
}
]
}
}
}
Bash
복사
•
평균 내기
# size=0을 조건으로 넣어서 분석결과만 출력하고 검색결과는 생략한다.
> curl -XGET "http://localhost:9200/books/_search?pretty" -H 'Content-Type: application/json' -d '{
"size": 0,
"aggs": {
"avg_pages": {
"avg": {
"field": "pages"
}
}
}
}
'
# pages의 평균값 출력
{
# ...
"aggregations" : {
"avg_pages" : {
"value" : 316.6666666666667
}
}
}
Bash
복사
